OpenClaw本地部署速度优化
OpenClaw本地部署速度优化
本地部署龙虾OpenClaw,发现速度比直接运行大模型要慢很多。其实那不是错觉,只需修改一下配置即可达到直接运行模型的速度。
设置上下文参数
OpenClaw会自动检测大模型支持的最大上下文,然后做为启动参数。
不同大小的上下文参数,显存&内存的分配也是不一样的。拿qwen3.5-9b举例,32K上下文和256K上下文,显存占用相差2倍,推理速度也会变慢,使用起来差别就更大。
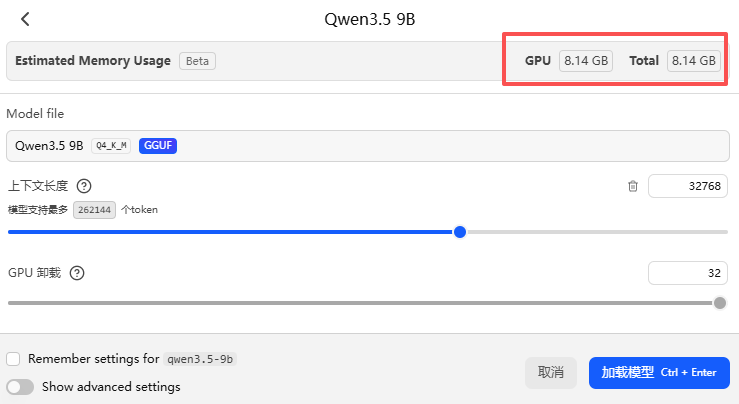
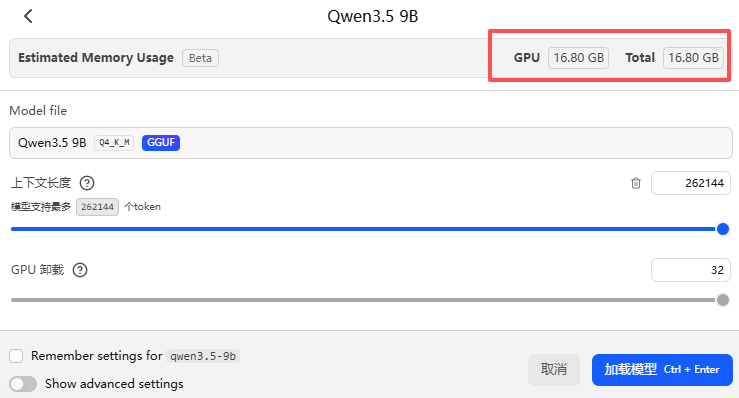
可以修改OpenClaw配置文件,手动指定上下文大小。
打开 .openclaw/openclaw.json ,找到使用的本地模型
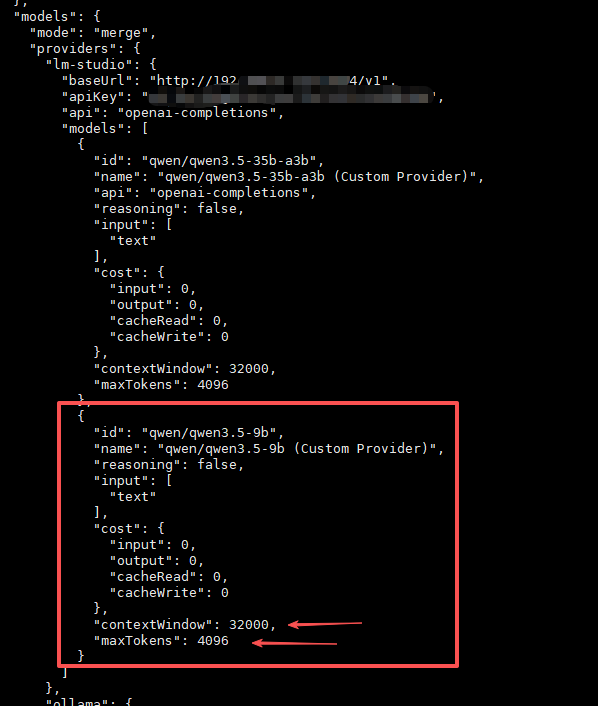
把最大上下文设为32K,最大词元设4K。具体视硬件性能设置。比如我用该模型,32K比较合适,在速度和能力上是甜点设置。
关闭推理
OpenClaw默认开启推理。如果机器性能一般,发“你好”都要思考半天。其实大部分任务都可以关闭推理,模型基本秒回,对于平时的对话,一般的任务都没什么影响。
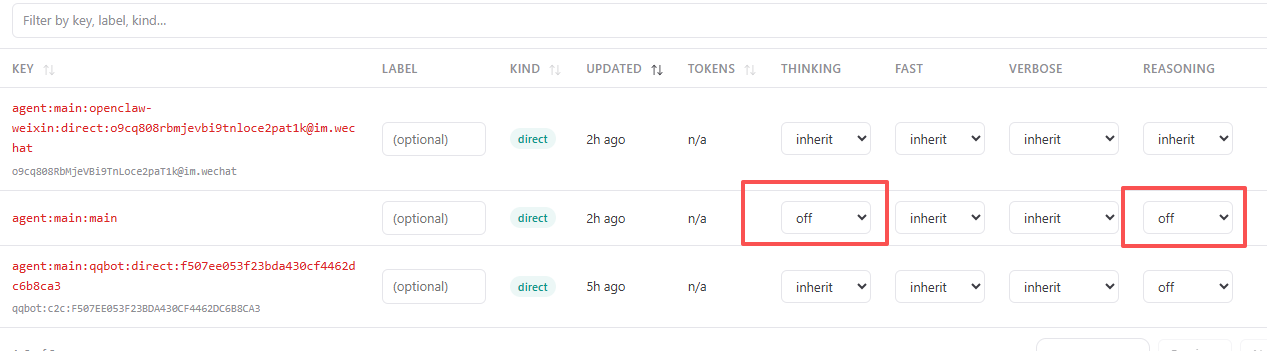
在OpenClaw管理后台,会话管理可以关闭推理。要处理复杂任务再开启。
经过如上两个设置后,OpenClaw速度提升好几倍,达到本地部署可用。
其他文章