Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar 这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。它们均提供标准化的数据水平扩展、分布式事务和分布式治理等功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。

ShardingSphere 是一个很活跃的项目,当前稳定版是 4.x ,预览版 5.x 及文档早已发布。ShardingSphere 早期 3.x 之前版本和 4.x 之后版本配置不兼容,而且从 4.x 开始才修复解析 select for update 语句问题,并且严格校验 schema ,不允许跨库查询。
本章基于 4.x 版本,使用 Sharding JDBC 实现分库分表,并配置 Sharding Proxy 和 Sharding UI 实现聚合查询。
Sharding JDBC
Sharding JDBC 定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 引入依赖
Sharding JDBC:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${version}</version>
</dependency>Spring JDBC 和 MySQL 驱动:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>- 配置
配置数据源
spring:
shardingsphere:
props:
show-sql: true # 打印sql语句,调试时可开启
datasource:
names: master1,slave1,slave2 # 配置三个数据源,主库master1,从库slave1和slave2
master1:
type: org.apache.commons.dbcp2.BasicDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://${MYSQL_HOST:localhost}:3307/engrz?useSSL=false&useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
username: ${MYSQL_USER:engrz}
password: ${MYSQL_PASSWORD:engrz2021}
slave1:
type: org.apache.commons.dbcp2.BasicDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://${MYSQL_HOST:localhost}:3308/engrz?useSSL=false&useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
username: ${MYSQL_USER:engrz}
password: ${MYSQL_PASSWORD:engrz2021}
slave2:
type: org.apache.commons.dbcp2.BasicDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://${MYSQL_HOST:localhost}:3309/engrz?useSSL=false&useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
username: ${MYSQL_USER:engrz}
password: ${MYSQL_PASSWORD:engrz2021}读写分离和分库分表
spring:
shardingsphere:
sharding:
master-slave-rules:
ds1: # 读写分离数据源,如果有多个库可配置多个
master-data-source-name: master1
slave-data-source-names: slave1,slave2
tables:
t_user_info: # 表名
actual-data-nodes: ds1.t_user_info_${0..9} # 规则,使用Groovy语法
table-strategy:
inline:
sharding-column: user_id # 分片字段
algorithm-expression: t_user_info_${user_id % 10}
t_user_log: # 表名
actual-data-nodes: ds1.t_user_log_$->{2019..2021} # 规则,使用Groovy语法
table-strategy:
standard:
sharding-column: log_date # 分片字段
precise-algorithm-class-name: com.engrz.commons.sharding.jdbc.algorithm.DatePreciseModuloShardingTableAlgorithm
range-algorithm-class-name: com.engrz.commons.sharding.jdbc.algorithm.DateRangeModuloShardingTableAlgorithmSharding JDBC 配置单纯的读写分离和分库分表的读写分离配置写法有一点差别
仅使用读写分离配置属性:spring.shardingsphere.masterslave.*
分库分表的读写分离配置属性:spring.shardingsphere.sharding.master-slave-rules.*
配置文件中分片说明:
t_user (用户表)
分10张表,user_id字段为long型主键,使用 user_id 值取模,把计算结果拼上表名,完整名如:t_user_info_0、t_user_info_1
t_user_log (用户日志表)
按年份分表,从2019到2021,使用自定义分片策略
DatePreciseModuloShardingTableAlgorithm:
/**
* 日期精确匹配
*/
public class DatePreciseModuloShardingTableAlgorithm implements PreciseShardingAlgorithm<Date> {
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Date> preciseShardingValue) {
Date date = preciseShardingValue.getValue();
Calendar c = Calendar.getInstance();
c.setTime(date);
String year = String.valueOf(c.get(Calendar.YEAR));
String tableName = null;
for (String tmp : collection) {
if (tmp.endsWith(year)) {
// 如果以当前年份结尾
tableName = tmp;
break;
}
}
if (null == tableName) {
String str = collection.iterator().next();
tableName = str.substring(0, str.lastIndexOf("_"));
}
return tableName;
}
}DateRangeModuloShardingTableAlgorithm:
/**
* 日期范围查询
*/
public class DateRangeModuloShardingTableAlgorithm implements RangeShardingAlgorithm<Date> {
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Date> rangeShardingValue) {
// 这里可以处理日期字段,避免多余查询
Range<Date> range = rangeShardingValue.getValueRange();
Integer start = null;
if (range.hasLowerBound()) {
Date lowerEndpoint = range.lowerEndpoint();
Calendar c = Calendar.getInstance();
c.setTime(lowerEndpoint);
start = Calendar.YEAR;
}
Integer end = null;
if (range.hasUpperBound()) {
Date upperEndpoint = range.upperEndpoint();
Calendar c = Calendar.getInstance();
c.setTime(upperEndpoint);
end = Calendar.YEAR;
}
if (null == start && null == end) {
return collection;
}
List<String> list = new ArrayList<>();
for (String tableName : collection) {
int suffix = Integer.parseInt(tableName.substring(tableName.lastIndexOf("_") + 1));
if (null != start && suffix < start) {
continue;
}
if (null != end && suffix > end) {
continue;
}
list.add(tableName);
}
return list;
}
}如果日志量大,还可以按季度分表,只要在方法中稍作修改,返回对应的表名即可。
关于 Sharding JDBC 的分片策略和分片算法,可查阅官方文档。
- 注意事项
- 使用分库分表后要注意主键唯一,可使用雪花算法生成主键
- 使用 Sharding JDBC 查询时尽量带上分库分表字段作为条件,避免全局扫描
- 主从模型中,事务中读写均用主库
- 某些sql语句不支持解析,如 distinct 和 group by 连用
- Sharding JDBC 4.x SQL 解析支持说明
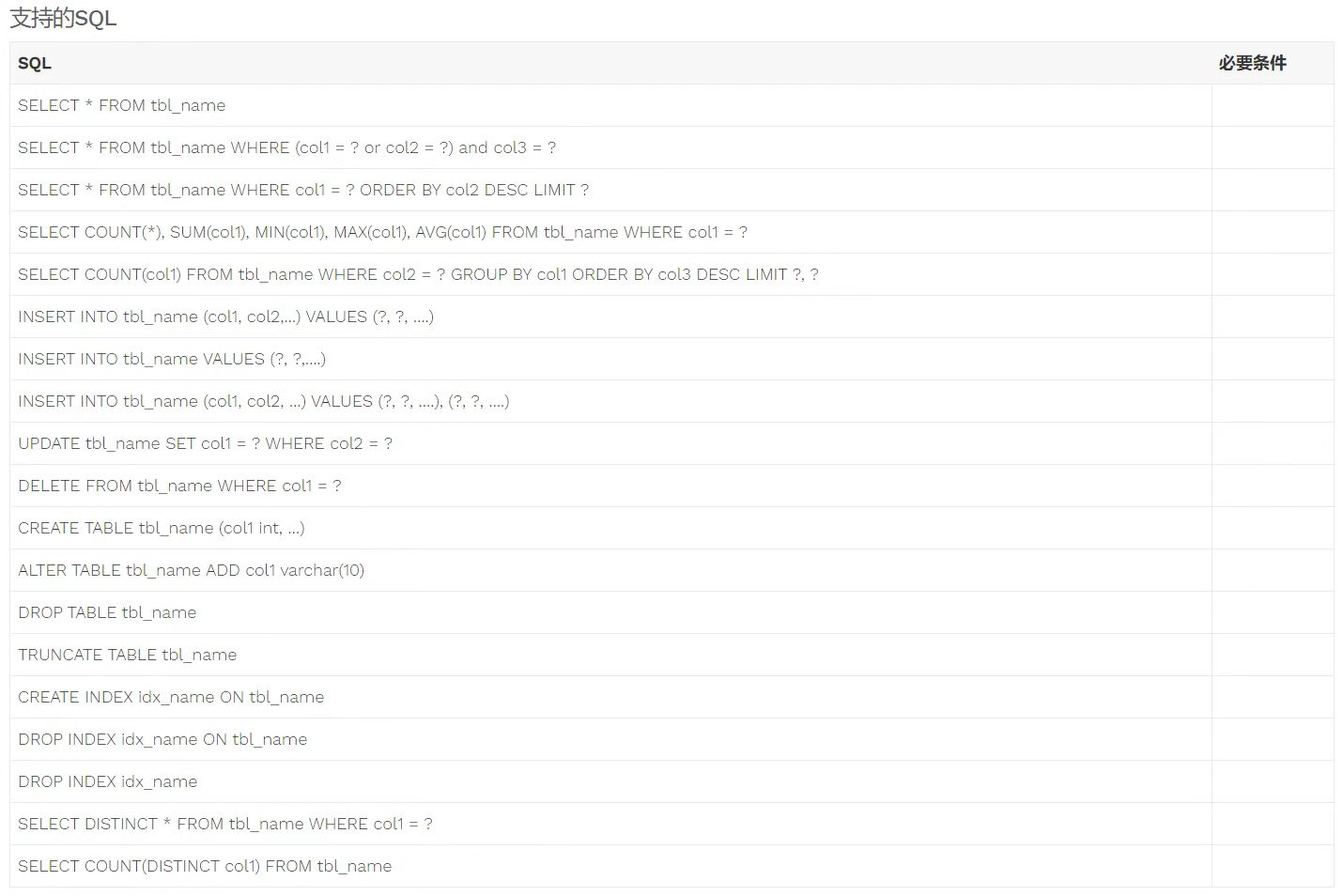
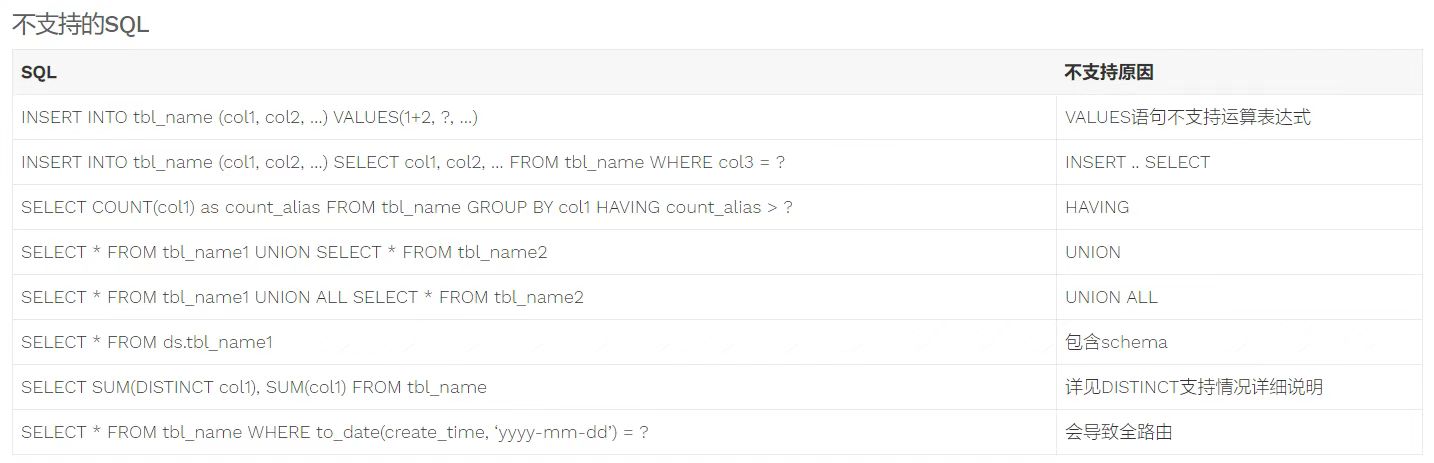
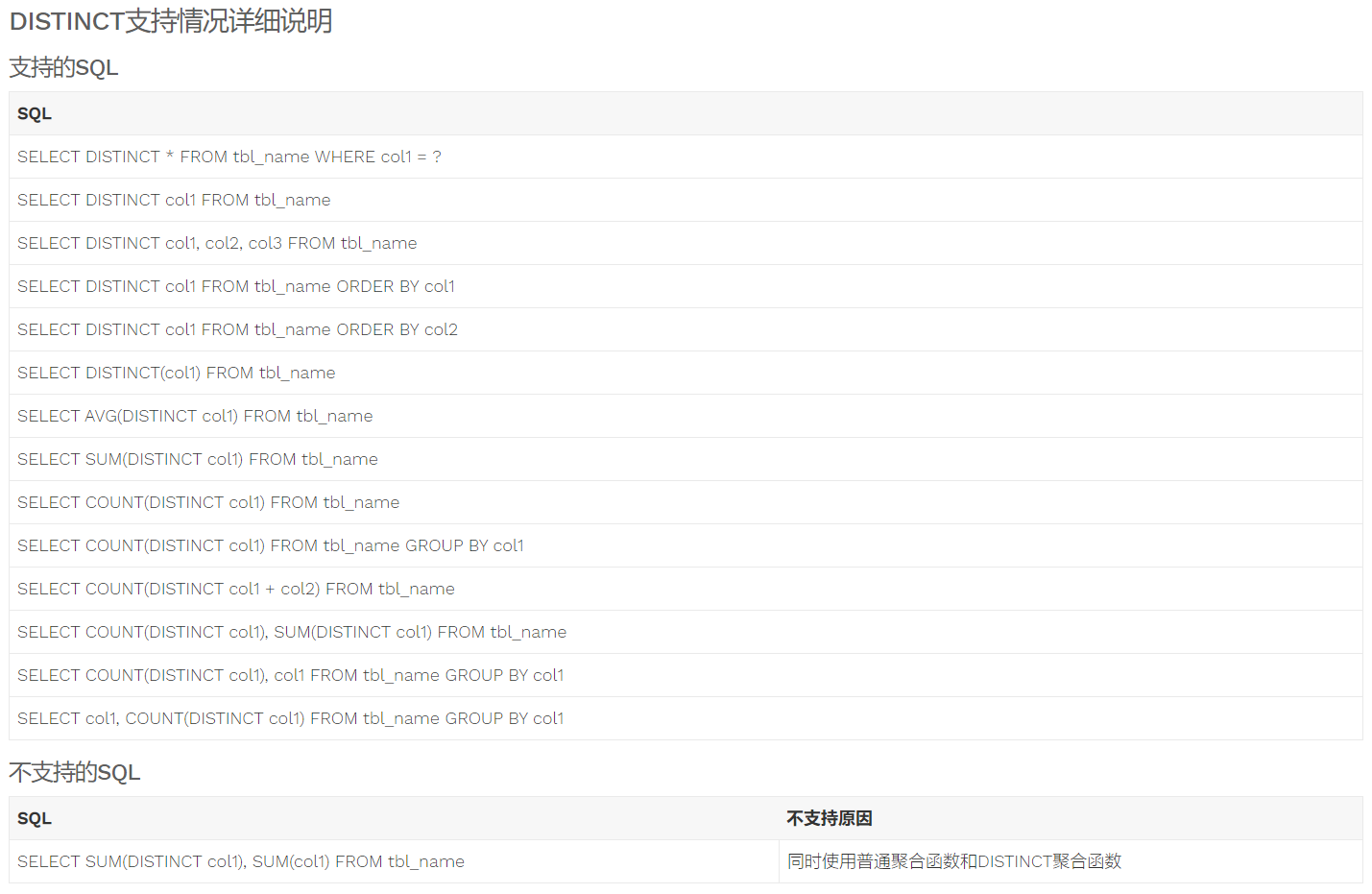
Sharding Proxy
Sharding Proxy 定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前先提供MySQL/PostgreSQL版本,它可以使用任何兼容MySQL/PostgreSQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat等)操作数据,对DBA更加友好。
使用 Sharding JDBC 分库分表后,数库落在不同的数据库和数据表中,使用 Sharding Proxy 作为代理,它会帮我们把上面的 t_user_0,t_user_1 … 聚合成一张 t_user 逻辑表。
Sharding Proxy 的安装配置请参考官方文档。如果有自定义分片算法,把代码打成JAR包放到 Sharding Proxy 解压后的conf/lib目录下。
实际使用中发现 Sharding Proxy 对连接的客户端有版本校验,比如我用 MySQL Workbench 8.0 无法连接 MySQL 5.7 的数据库。可以使用 DBeaver 客户端,手动指定与服务端版本对应的驱动。
Sharding UI
Sharding UI是 ShardingSphere 的一个简单而有用地web管理控制台。它用于帮助用户更简单的使用 ShardingSphere 的相关功能,目前提供注册中心管理、动态配置管理、数据库编排等功能。
Sharding UI 和 Sharding Proxy 方便我们管理数据库,在理解 Sharding JDBC 分库分表后配置十分简单,可参考 Sharding Sphere 4.x 相关文档