使用核显加速AI模型运行
开源大模型平台Ollama,从 v0.12.6 开始支持 Vulkan ,方便用核显加速AI模型运行。我在一台 12700HK (windows) 的笔记本和一台 i7-7700K (linux) 台式机使用GPU运行AI模型。资源使用率原来CPU 100%,在用GPU运行后,CPU使用基本降为0%。
Intel 从第6代酷睿 (Skylake) 开始提供官方 Vulkan 支持。而 AMD 几乎所有 APU 都支持 Vulkan 。
魔塔社区-英特尔亚太研发有限公司出了一个 Ollama 英特尔优化版,仅支持Windows,Ollama 平台版本跟不上官方的更新,新模型无法运行。既然官方支持核显加速,还是优先选择官方Ollama 。
开启Vulkan
Ollama 默认情况下,Vulkan 未开启,需要设置环境变量:OLLAMA_VULKAN="1"
- Windows
如果系统是Windows,可以在资源管理器找到Ollama进程结束。也可以在cmd中用命令查找进程,再用 taskkill 结束。
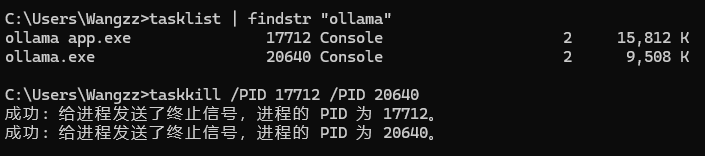
tasklist | findstr "ollama"
taskkill /PID 进程ID /PID 进程ID
结束进程后,设置环境变量,并重启Ollama:
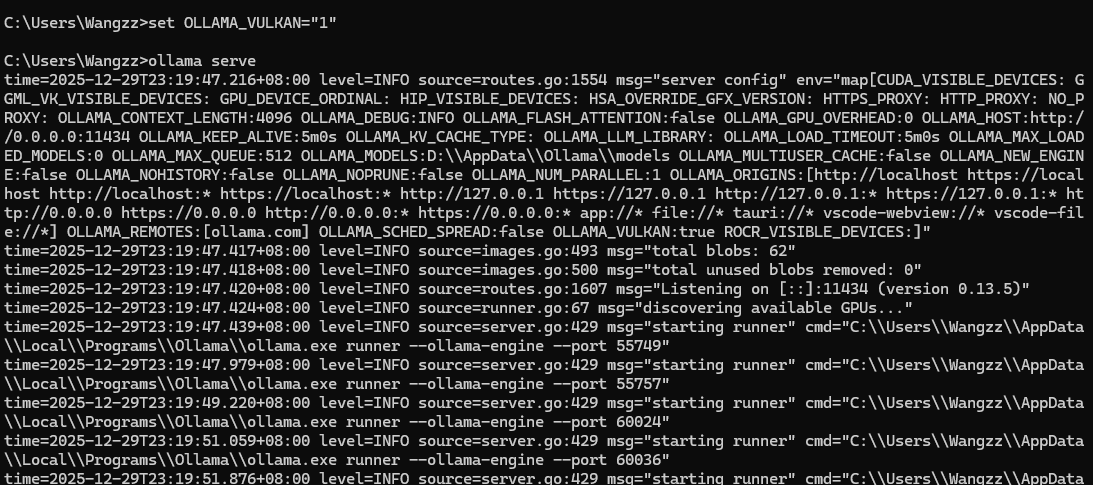
set OLLAMA_VULKAN="1"
ollama serve
再重新开个CMD窗口,用ollama命令运行AI模型
- Linux
如果系统是Linux,可以先关闭Ollama服务,再设置环境变量,并重启Ollama:
# 停止ollama服务
systemctl stop ollama
#设置环境变量
export OLLAMA_VULKAN="1"
# 启动ollama
ollama serve
如果希望以后开机都默认启用Vulkan,可以把环境变量写在服务里。
编辑配置文件
vi /etc/systemd/system/ollama.service.d/environment.conf
加上环境变量
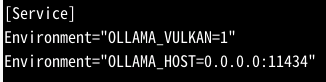
保存后重新加载:
# 刷新配置
systemctl daemon-reload
# 重启服务
systemctl restart ollama
运行效果

我的系统是linux,运行qwen3:4b-instruct 。使用intel_gpu_top查看,可以看到有ollama进程在使用:
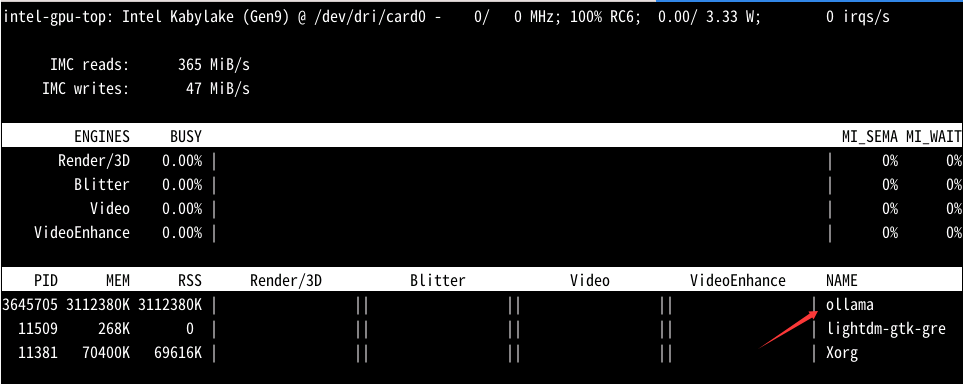
建议
使用GPU运行AI模型,确实让CPU算力解脱出来。我在 i7-7700K 上用GPU跑AI模型速不如CPU,在 12700HK GPU上效果和CPU持平,推理会稍快一点。建议Intel 12代及以后的核显使用GPU运行,12代以前的用CPU跑。模型参数量用4b及以下的效果会好些,可以满足一些轻量工作需求。
附上一些Ollama常用命令参数:
ollama run qwen3:4b --verbose --keepalive=1h --think=false
--verbose: 输出日志信息
--keepalive: 在内存中存留时间,默认5m(5分钟),1h(1小时)。如果设为-1m或-1h,会永久保存,除非手动停止
--think: 默认true,开启推理。非必要情况关闭推理可以更快响应
更多ollama参数见官方文档。